网络爬虫(Web Crawler)是一种自动化程序,其主要目的是系统地浏览和索引互联网上的网页内容。具体来说,网络爬虫通过遵循网页之间的链接,从一个页面跳转到另一个页面,从而遍历整个网站或整个互联网。它的核心功能是收集和整理网页数据,以便搜索引擎或其他系统能够快速检索和提供相关信息。
搜索引擎依赖于爬虫来自动访问和下载网页内容,并将其存储在数据库中,以便用户在搜索时能够快速找到相关结果。例如,Googlebot、Bingbot等搜索引擎的爬虫会定期访问网页,更新其索引,以确保搜索结果的准确性和时效性。
除了搜索引擎,网络爬虫还被广泛应用于数据收集和分析领域。例如,企业可以使用爬虫来监控市场价格变化、新闻更新、竞争对手动态等信息,从而支持市场分析和决策制定。此外,爬虫还可以用于学术研究,收集特定领域的数据进行统计分析。
网络爬虫可以用于自动化检查网站的链接是否有效,验证HTML代码是否正确,以及检测网站是否存在技术问题(如重复内容、死链等)。这些功能有助于提高网站的性能和用户体验。
一些网站和应用程序使用爬虫来聚合来自不同来源的内容,例如新闻聚合器、RSS订阅服务等。通过爬虫,这些服务可以自动抓取最新的文章、视频或其他媒体内容,并将其整合到用户界面中。
虽然大多数网络爬虫专注于公开的网页内容,但也有专门的爬虫用于访问深网(Deep Web)或不可见的网页内容。这些内容通常需要通过特定的查询或登录才能访问,因此需要更复杂的爬虫策略。
在商业领域,网络爬虫被用于数据挖掘和商业智能分析。例如,通过爬取社交媒体、电商平台等网站的数据,企业可以了解消费者行为、市场趋势和竞争对手的策略。
网络爬虫的主要目的是通过自动化方式系统地浏览和索引互联网内容,从而为搜索引擎、数据分析、网站维护、内容聚合等应用提供支持。它不仅提高了信息检索的效率,还在多个领域中发挥着重要作用。
什么是网络爬虫?
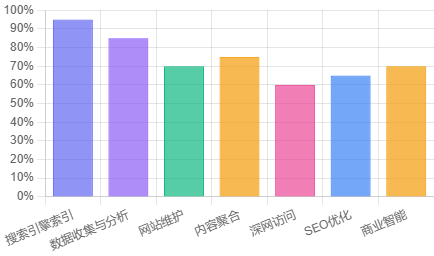
网络爬虫的主要作用
核心概念
网络爬虫的主要功能
为搜索引擎提供索引
数据收集与分析
网站维护与优化
内容聚合与RSS订阅
深网与不可见内容的访问
数据挖掘与商业智能
总结
什么是网络爬虫(Web Crawler)?
作者:zvvq博客网
免责声明:本文来源于网络,如有侵权请联系我们!