现代浏览器自动化工具的全面解析与应用实践
有效处理JavaScript渲染的网站,确保数据完整捕获
支持Chromium、Firefox、WebKit的桌面和移动端
处理无限滚动、懒加载、嵌套iframe等复杂UI结构
Playwright 是微软于2020年推出的开源浏览器自动化工具,专为现代Web应用设计。它提供了统一的API来控制多种浏览器引擎,包括Chromium、Firefox和WebKit,并且支持桌面和移动设备的自动化测试。
通过 sync_playwright() 启动浏览器,headless=False 可启用调试模式
通过执行JavaScript滚动页面并检测高度变化,捕获动态加载的内容
使用 page.route() 屏蔽图片请求或修改HTML内容
通过 scrapy-playwright 库结合 Scrapy 框架,处理 JavaScript 页面并保存至数据库
内置 screenshot() 方法可捕获全页或指定区域,用于调试或验证页面状态
通过 page.on('response') 拦截请求和响应,分析数据流
记录测试过程(包括屏幕、DOM快照),通过 playwright show-trace 回放
结合 try/except 和超时设置增强鲁棒性,确保爬虫稳定运行
采用模块化设计,将页面对象、测试逻辑和数据处理分离
使用异步API实现并发抓取,提高效率但需注意速率限制
Playwright 网页抓取技术指南
动态内容处理
多浏览器支持
复杂交互能力
Playwright 简介
核心优势
适用场景
技术实现详解
启动与配置
Python 示例
from playwright.sync import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto('https://example.com')
# ... 执行抓取操作 ...
context.close()
browser.close()
代理与认证
# 配置代理
context = browser.new_context(
proxy={"server": "per-context"},
user_agent="Custom User Agent"
)
# 保存登录状态
context = browser.new_context(storage_state="auth.json")
# 读取已保存的登录状态
context = browser.new_context()
context.add_init_script("localStorage.setItem('__Secure-next-auth.session-token', 'your_token');")
页面交互
滚动加载
def scroll_page(page):
last_height = page.evaluate('document.body.scrollHeight')
while True:
page.evaluate('window.scrollTo(0, document.body.scrollHeight)')
new_height = page.evaluate('document.body.scrollHeight')
if new_height == last_height:
break
last_height = new_height
time.sleep(1) # 等待新内容加载
事件等待
# 等待特定选择器出现
page.wait_for_selector('.product-item')
# 等待元素可见
page.wait_for_selector('#cart', timeout=60000)
# 使用 expect 断言
from expect_webdriver import expect
expect(page).to_have_url('https://example.com/products')
请求拦截
过滤资源
page.route("**/*.{png,jpg,jpeg,svg}", lambda route: route.abort())
# 或者修改响应
page.route("**/api/data", lambda route: route.continue_(response="modified_content"))
网络监控
# 监听所有响应
page.on("response", lambda response: print(f"拦截到响应: {response.url}"))
# 拦截特定API请求
page.route("**/api/products", lambda route: {
"status": 200,
"body": '{"products": []}'
})
数据提取与存储
数据提取方法
元素定位
# 使用CSS选择器
title = page.querySelector("h1").text_content()
titles = page.querySelectorAll(".product-title")
# 使用Playwright的 locator API
product_name = page.locator("#product-name").text_content()
product_price = page.locator(".price").first.text_content()
属性提取
# 获取href属性
links = page.querySelectorAll("a")
for link in links:
href = link.get_attribute("href")
print(href)
# 获取data属性
data_id = page.querySelector(".item").get_attribute("data-id")
数据存储格式
JSON文件
import json
products = [
{"name": "Product 1", "price": "$10"},
{"name": "Product 2", "price": "$20"}
]
with open("products.json", "w") as f:
json.dump(products, f, indent=2)
CSV文件
import csv
with open("products.csv", "w", newline="") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=["name", "price"])
writer.writeheader()
writer.writerows(products)
Scrapy集成
# 安装 scrapy-playwright 插件
pip install scrapy-playwright
# 在 scrapy 项目中启用
EXTENSIONS = {
'scrapy_playwright.PlaywrightExtension': 500,
}
# 使用 scrapy-playwright 命令
scrapy crawl products --playwright --playwright-browsers chromium
高级功能与调试
截图与录屏
# 全页截图
page.screenshot(path="full_page.png", full_page=True)
# 指定区域截图
page.screenshot(path="element.png", clip={"x": 100, "y": 100, "width": 200, "height": 100})
# 录制视频
browser.new_context(record_video_dir="videos/")
网络监控
# 监听所有请求和响应
page.on("request", lambda request: print(f"发送请求: {request.url}"))
page.on("response", lambda response: print(f"接收响应: {response.url}"))
# 拦截特定请求
page.route("**/api/data", lambda route: route.continue_())
追踪功能
# 启用追踪
context = browser.new_context(trace_dir="trace/")
page = context.new_page()
# 运行测试
page.goto("https://example.com")
# 生成报告
import asyncio
asyncio.run(playwright.show_trace("trace.zip"))
性能优化与扩展
性能提升
云服务集成
错误处理
try:
page.click("#submit-button", timeout=60000)
except TimeoutError:
print("元素未在规定时间内出现")
# 处理其他异常
except Exception as e:
print(f"发生错误: {e}")
# 记录日志或重试逻辑
注意事项
反爬策略
认证挑战
技术对比
Playwright vs Selenium
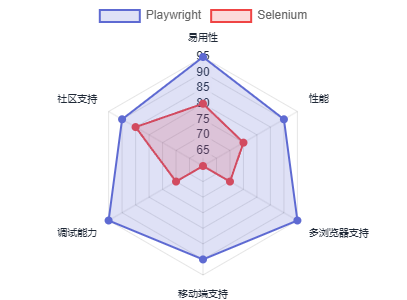
主要区别
Playwright vs Puppeteer
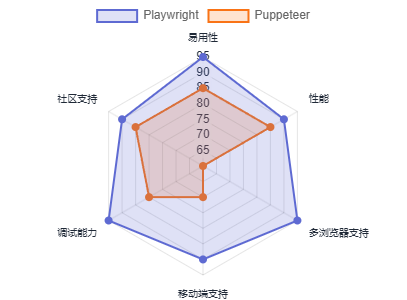
主要区别
最佳实践
代码组织
# 项目结构示例
project/
├── config.py # 配置文件
├── helpers.py # 辅助函数
├── pages/ # 页面对象模型
│ └── product_page.py
├── tests/ # 测试脚本
│ └── test_products.py
├── utils/ # 工具类
│ └── data_parser.py
└── main.py # 主程序入口
并发策略
from playwright.async_api import async_playwright
import asyncio
async def run_concurrent_tasks():
async with async_playwright() as p:
browser = await p.chromium.launch()
tasks = []
for i in range(5): # 并发5个任务
context = await browser.new_context()
page = await context.new_page()
tasks.append(
asyncio.create_task(scrape_page(page, i))
)
await asyncio.gather(*tasks)
await browser.close()
async def scrape_page(page, index):
# 页面抓取逻辑
pass
Playwright自动化工具,Playwright 网页抓取技术指南
作者:zvvq博客网
JavaScriptPythonJavaTypeScriptC#
免责声明:本文来源于网络,如有侵权请联系我们!