在2025年的高度竞争数字市场中,快速收集、分析并采取行动于竞争对手情报的能力已不再是奢侈品,而是基本的商业必需品。本报告提供了一套全面的技术指南,详细介绍如何使用Python编程语言及其丰富的生态系统构建强大、可扩展且智能的竞争对手分析系统。
本研究深入探讨了自动化分析流水线的完整生命周期,从理解现代网站数据获取的法律和技术复杂性开始。它涵盖了绕过复杂反爬虫措施的高级技术,详细说明了分析竞争对手价格和公众情感的核心工作流程,并展示了使用云原生和大数据技术部署这些系统的架构蓝图。
从周期性手动审查转向持续的数据驱动战略调整
Python + 云服务 + AI分析 + 实时处理
企业决策者、数据工程师、市场分析师
任何自动化分析系统的基础都是为其提供动力的数据。从竞争对手网站获取数据的主要方法是网络爬虫。然而,在编写第一行代码之前,必须充分理解治理这一实践的法律和技术环境。
Python提供了丰富的网络爬虫库,适用于各种复杂度:
网络爬虫存在于法律灰色地带,不当执行可能导致IP封锁、法律挑战和声誉损害。坚持严格的道德框架是不可协商的。
关键原则:爬取数据应以不干扰人类用户正常使用网站服务为目标
现代网站很少是静态的。它们是动态应用程序,配备了旨在阻止爬虫的复杂反爬虫技术。成功的自动化策略必须预见并克服这些防御。
许多网站使用JavaScript在初始页面加载后动态加载内容。简单的requests调用只会检索初始HTML骨架,而缺少关键数据。为了解决这个问题,需要浏览器自动化工具。
动态网页内容爬取技术对比
顶级反爬虫服务如Cloudflare和DataDome提出了重大挑战。它们使用浏览器指纹、JavaScript挑战和行为分析等先进技术来区分机器人和人类。
重要提示:这是一个持续的"军备竞赛"。开源工具可能因反爬虫系统的演变而过时,使商业解决方案或复杂的定制工具成为可靠长期爬虫操作的必要条件。
在建立可靠的数据获取后,下一步是提取可操作的情报。本节详细介绍了两个主要分析工作流:竞争对手价格和公众情感。
此工作流专注于跟踪价格、促销和库存状态,以支持动态定价策略和竞争定位。
此工作流通过分析产品评论、社交媒体和新闻文章中的文本数据来衡量公众感知,揭示竞争对手的优势和劣势。
库的选择取决于所需的准确性和复杂度:
概念验证脚本不足以支持持续的大规模监控。需要健壮、可扩展和可靠的生产架构。以下是两种现代架构模式。
此架构适合初创企业和中型运营,提供成本效益和最小的运营开销下的自动扩展。
AWS无服务器架构数据流
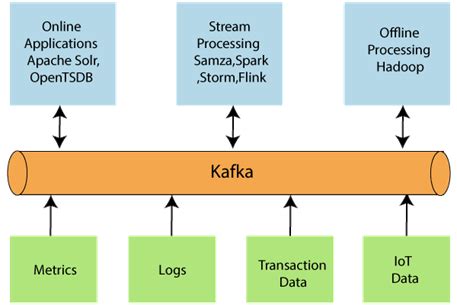
对于跟踪数千个产品近乎实时的企业,需要更强大的流处理架构。
Kafka与Spark实时数据流水线架构
对于具有许多依赖关系的复杂批处理流水线,专用工作流编排器是必不可少的。Apache Airflow是原生Python工具,允许您将工作流定义为有向无环图(DAG),确保任务按正确顺序运行并在失败时处理重试。
最佳实践:根据工作流复杂度选择合适的编排工具,确保任务依赖关系清晰,监控到位
使用Python自动化竞争对手和基准分析已从一种利基技术能力转变为核心战略功能。本报告中详细说明的方法——从道德地导航数据获取、赢得反爬虫军备竞赛到实施先进的AI驱动分析以及部署可扩展的云架构——为构建强大的竞争情报引擎提供了路线图。
AI驱动的工具将能够自动适应网站布局变化,减少传统爬虫的脆弱性。
分析将超越基本情感,采用更精细的技术如基于方面的 sentiment 分析(ABSA),可以识别对竞争对手产品特定功能的情感。
爬虫和反爬虫技术之间的战斗只会加剧。成功将需要在先进技术和机器学习方面持续投资。
通过拥抱自动化并利用Python生态系统的强大功能,企业可以确保他们不仅对市场做出反应,而是基于对竞争格局的持续、全面和实时的理解来主动塑造战略。建立这种能力将成为未来五年内领先企业的关键差异化因素。
报告概述
核心价值
技术栈
目标受众
第一部分:数据获取基础
1.1 Python网络爬虫工具包
基础库
高级框架
1.2 导航2025年的法律与伦理迷宫
法律合规要点
伦理与责任
第二部分:高级爬虫技术
2.1 处理动态JavaScript渲染内容
主流解决方案
技术优势

2.2 绕过高级反爬虫系统:Cloudflare & DataDome
多管齐下策略
行为模拟
第三部分:核心分析引擎
3.1 工作流1:自动化竞争对手价格与基准分析
技术工作流:
3.2 工作流2:自动化竞争对手情感分析
Python情感分析AI工具包:
简单快速(基于规则)
强大且上下文感知(深度学习)
技术工作流:
第四部分:生产级架构
4.1 架构1:可扩展无服务器流水线(AWS)
数据流:
无服务器架构图
触发器
爬虫
存储
分析
4.2 架构2:实时大数据流水线(Kafka & Spark)
数据流:
4.3 工作流编排
Airflow特点
GitHub Actions
结论与未来展望
2025年及未来趋势
超级自动化爬虫
更深入的NLP洞察
持续的军备竞赛
最终建议
使用Python构建智能竞争对手分析系统:技术指南与最佳实践
作者:zvvq博客网
EventBridge
Lambda
S3
DynamoDB
免责声明:本文来源于网络,如有侵权请联系我们!