本指南综合了多篇文献资料,提供了一系列技术手段和策略,帮助您在不被网站封禁的情况下进行网页爬取。通过模拟人类行为、使用代理和轮换IP、优化请求头等方法,可以显著降低被封风险。
避免网站封禁的网页爬取策略
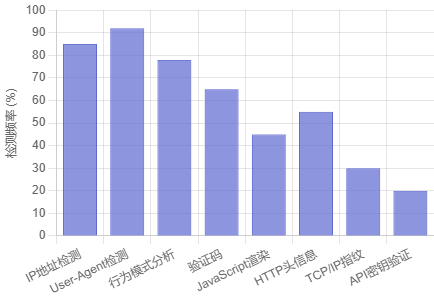
反爬虫检测技术分布
常见反爬虫检测技术
推荐应对策略
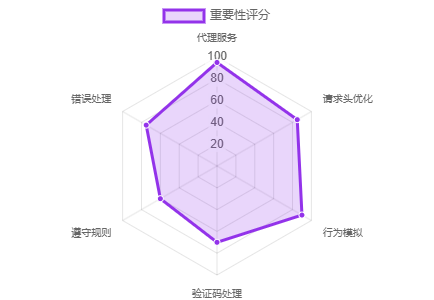
核心策略详解
使用代理服务器与轮换IP
- 通过代理服务器隐藏真实IP,避免因频繁请求被封
- 使用代理池自动切换IP地址,避免单个IP被封
- 避免使用共享代理或廉价代理,选择提供动态IP和地理位置伪装的服务
模仿人类行为
- 在请求间添加随机延迟(如1-5秒),避免触发速率限制
- 模拟人类的非规律性操作,如随机滚动、点击无关链接等
- 使用无头浏览器(如Puppeteer、Selenium)渲染页面,模拟真实用户交互
优化HTTP请求头
- 使用真实浏览器的User-Agent字符串,并定期更换
- 设置Accept、Accept-Language、Referrer等字段,模拟真实浏览器请求
- 确保TCP参数(如TTL、窗口大小)与真实设备一致,避免被TCP/IP指纹识别
处理反爬机制
- 使用第三方服务(如Anti-Captcha、ScrapingBee)或OCR技术自动解决验证码
- 检查网页中隐藏的不可见链接(如CSS设置display: none),避免触发反爬机制
- 使用支持Cloudflare bypass的工具(如Bright Data、Apify),绕过WAF
遵守网站规则与法律
- 严格遵守robots.txt文件中的规则,仅爬取允许的页面
- 避免爬取受版权保护的内容、私人数据或违反网站条款的数据
- 若涉及欧盟用户数据,需遵守GDPR,避免非法收集个人信息
技术工具与框架
- 使用Puppeteer(Node.js)、Selenium(Python/Java)等工具模拟浏览器行为
- Scrapy(Python)、Playwright(Node.js)等支持分布式爬取和反爬策略
- 使用托管服务(如Apify、Crawlbase)简化反爬处理,专注于数据提取
其他优化策略
- 避免一次性爬取大量数据,分批次、分时段进行
- 将爬取结果直接存储到云服务(如AWS S3、Google Cloud Storage),减少本地资源占用
- 实现重试机制和异常捕获,避免因单点失败导致IP被封
最佳实践总结
成功爬取的关键在于平衡技术手段与伦理合规。通过模拟人类行为、使用代理和轮换IP、优化请求头,并严格遵守网站规则,可显著降低被封风险。
关键要点
- 始终尊重网站的robots.txt规则
- 使用高质量代理服务,避免共享IP
- 模拟真实用户行为,避免机械式请求
- 合理控制请求频率,避免服务器过载
- 必要时使用合法的第三方服务辅助爬取
免责声明:本文来源于网络,如有侵权请联系我们!