使用Python从网站抓取数据的完整教程
首先,你需要知道你要抓取数据的网站的具体URL。确保目标网站允许爬虫访问,并且你有权限获取其数据。
使用
使用
通过查找特定的HTML标签和属性来提取你需要的数据。例如,提取所有的段落文本:
将提取的数据存储到文件中,如CSV、JSON等格式。例如,使用
如果目标网站使用JavaScript动态加载内容,可以使用
在进行网页抓取时,请确保遵守相关法律法规和网站的使用条款,不要对目标网站造成过大负担。
Python网络爬虫指南
确定目标URL
发送HTTP请求
requests库来发送HTTP请求,获取网页的HTML内容。
import requests
url_to_parse = "https://example.com"
response = requests.get(url_to_parse)
html = response.text
解析HTML内容
BeautifulSoup库来解析HTML内容。BeautifulSoup可以帮助你轻松地导航和搜索HTML文档。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
提取所需数据
paragraphs = soup.find_all('p')
for p in paragraphs:
print(p.text)
存储数据
csv库将数据写入CSV文件:
import csv
with open('data.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Title', 'Content'])
for p in paragraphs:
writer.writerow([p.text])
处理动态内容
Selenium或Playwright等工具来模拟浏览器行为,抓取动态生成的内容。例如,使用Playwright:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto('https://example.com')
content = page.content()
browser.close()
soup = BeautifulSoup(content, 'lxml')
# 继续解析和提取数据
遵守法律法规
Python爬虫技术对比
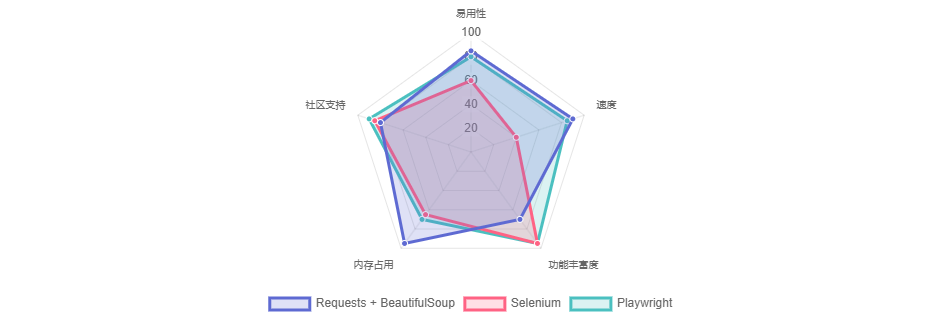
最佳实践建议
Python网络爬虫指南-使用Python从网站抓取数据的完整教程
作者:zvvq博客网
1
2
3
4
5
6
7
免责声明:本文来源于网络,如有侵权请联系我们!