本文档介绍了如何从网站的robots.txt文件中抓取所有允许的页面。通过遵循这些步骤,您可以确保在爬取过程中遵守网站的规定和最佳实践,同时获取所需的数据。
robots.txt是网站管理员用来指导网络爬虫(如搜索引擎爬虫)如何抓取网站内容的文件。它指定了哪些页面可以被抓取,哪些页面不可以被抓取,以及抓取的频率等。
遵守robots.txt文件可以帮助您避免访问受限资源,减少服务器负载,并确保您的爬虫行为符合网站的使用条款。这也有助于维护良好的网络公民形象。
robots.txt文件是网站管理员用来指导网络爬虫(如搜索引擎爬虫)如何抓取网站内容的文件。它指定了哪些页面可以被抓取,哪些页面不可以被抓取,以及抓取的频率等。
例如,可以通过访问
使用Python的robotparser模块来读取和解析robots.txt文件。这个模块可以帮助你判断是否可以抓取某个特定的URL。
这段代码首先设置了robots.txt文件的URL,然后读取并解析该文件。
在解析了robots.txt文件之后,使用
如果robots.txt文件允许抓取某个页面,你可以使用requests库来获取该页面的HTML内容。
这段代码首先检查是否允许抓取该页面,如果允许,则发送HTTP GET请求获取页面内容,并使用BeautifulSoup解析HTML。
如果网站有多个页面需要抓取,通常会有一个分页机制(如"Next"或"Previous"按钮)。你需要检查每个页面上的这些元素,并相应地导航到下一页。
为了避免对网站造成过多请求,每次请求之间添加延迟。可以使用
实现适当的错误处理和异常处理,以处理抓取过程中可能发生的任何错误。
将提取的数据存储在适当格式中(如CSV、JSON或数据库)。
首先在少量页面上测试抓取器,确保其正确工作。在测试中遇到任何问题时进行调试。
可以通过打印中间结果或使用调试工具来帮助调试。
注意网站的服务条款和robots.txt文件,确保负责任地抓取,不损害网站或违反任何规则。
在抓取前检查网站的合法性和服务条款总是好的实践。
根据网站流量和服务器负载能力,合理设置请求间隔,避免触发反爬虫机制。
严格遵守robots.txt中定义的爬取规则,特别是对于禁止爬取的路径和用户代理。
为网络请求和数据解析添加完善的异常处理机制,确保程序的稳定性和可靠性。
概述
什么是robots.txt?
为什么需要遵守robots.txt?
抓取步骤
理解robots.txt文件
https://[domain name].com/robots.txt来查看目标网站的robots.txt文件。
读取robots.txt文件
is_allowed函数用于检查特定的URL是否允许被抓取。
检查允许抓取的页面
is_allowed函数来检查你想要抓取的每个页面是否被允许。
抓取页面内容
处理分页
添加适当延迟
time.sleep()函数来实现。
处理错误
存储数据
测试和调试
尊重网站政策
抓取效率分析
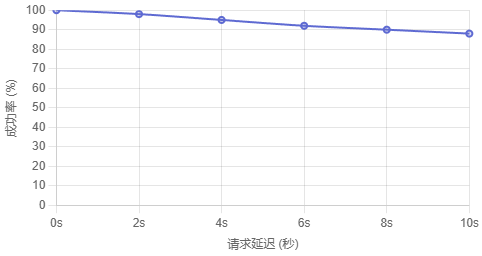
请求延迟与成功率
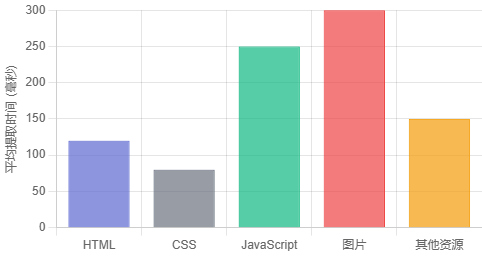
数据提取效率
最佳实践
合理设置请求间隔
尊重robots.txt规则
处理异常情况
从robots.txt文件中抓取网站页面
作者:zvvq博客网
1
2
3
4
5
6
7
8
9
10
免责声明:本文来源于网络,如有侵权请联系我们!