pika 是 360 基础架构团队和 dba 团队联合研发的一款高效、稳定、简单可依赖的开源的 nosql 数据库产品。完全兼容 redis 协议,支持 5 种数据结构(string,hash,list,set,zset),数据持久化到 rocksdb,相比于 redis 内存的存储方式,能极大减少服务器资源的占用,增强了数据的可靠性。可以采用单机和集群两种模式部署。pika 项目 2015 年启动,随后在 github 上开源,现有 3700 stars,35个 contributors,社区有大量的线上业务使 pika。 copyright zvvq
对比 Redis
存储容量: Redis 存储到内存,硬件成本高,宕机恢复延迟高;Pika 借用 RocksDB 存储到磁盘,单台服务器所容纳的数据量是 Redis 的几十倍,宕机恢复速度快。
内容来自zvvq,别采集哟
吞吐量: Redis QPS 更高,单台服务器百万级的 QPS;Pika QPS 相对较低,单服务器几十万,Redis 是 Pika 的 3~5 倍。 zvvq好,好zvvq
访问延迟: Redis 应该在 1ms 以内;Pika 延迟稍高,3ms 以内。 内容来自samhan
运维部署: Redis 支持单机主从和集群两种方式; Pika 也支持两种方式部署。 本文来自zvvq
适用场景
如果业务场景数据量比较大(> 50GB),数据可靠性要求高,那么 Pika 可以解决您的问题。 内容来自zvvq
场景1:大规模数据处理系统的中间结果存储
场景2:使用 Redis/Redis Cluster 做持久化存储的业务系统
场景3:大型分布式系统的元数据存储 内容来自samhan
架构设计
Pika 可以通过配置文件中的 instance-mode 配置项,设置为 classic 和 sharding,来选择运行经典模式(Classic)还是分布式模式(Sharding)的 Pika。 copyright zvvq
经典模式架构
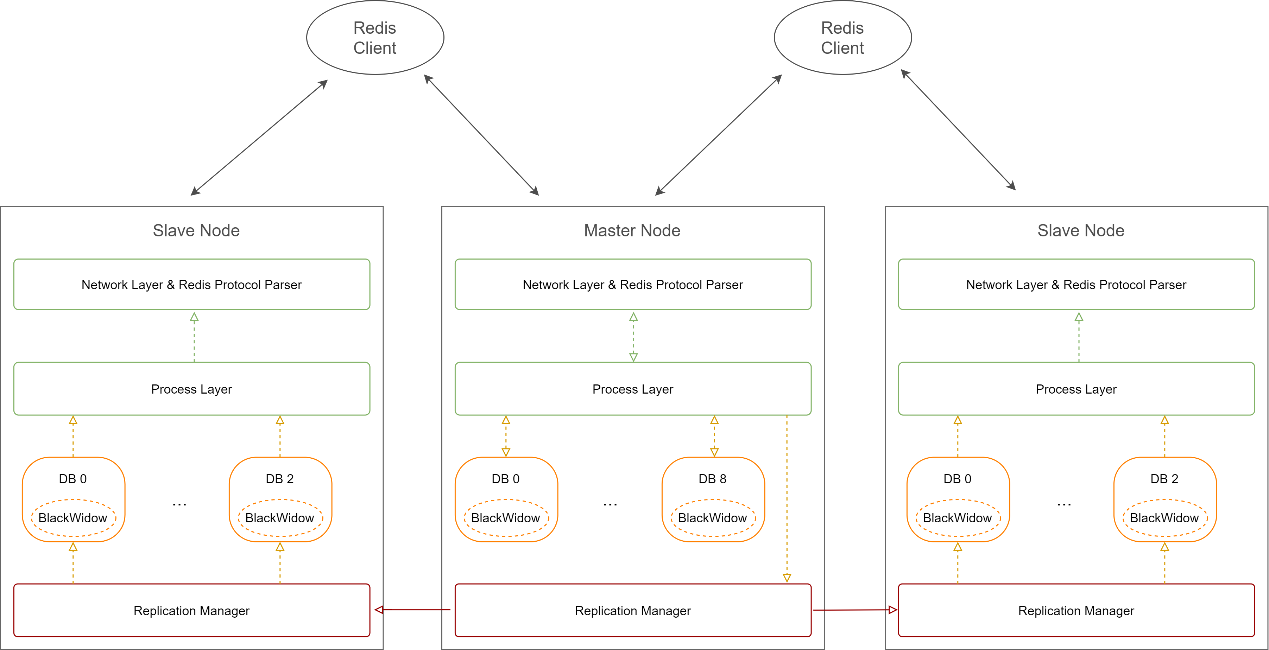
内容来自samhan
经典模式(Classic): 即1主N从同步模式,1 个主实例存储所有的数据,N 个从实例完全镜像同步主实例的数据,每个实例支持多个 DBs。Pika 的配置项 databases 允许您设置可以创建的最大 DB 数量,默认从 0 开始。DB 在 Pika 上的物理存在形式是一个文件目录。 内容来自samhan
分布式模式架构
内容来自samhan
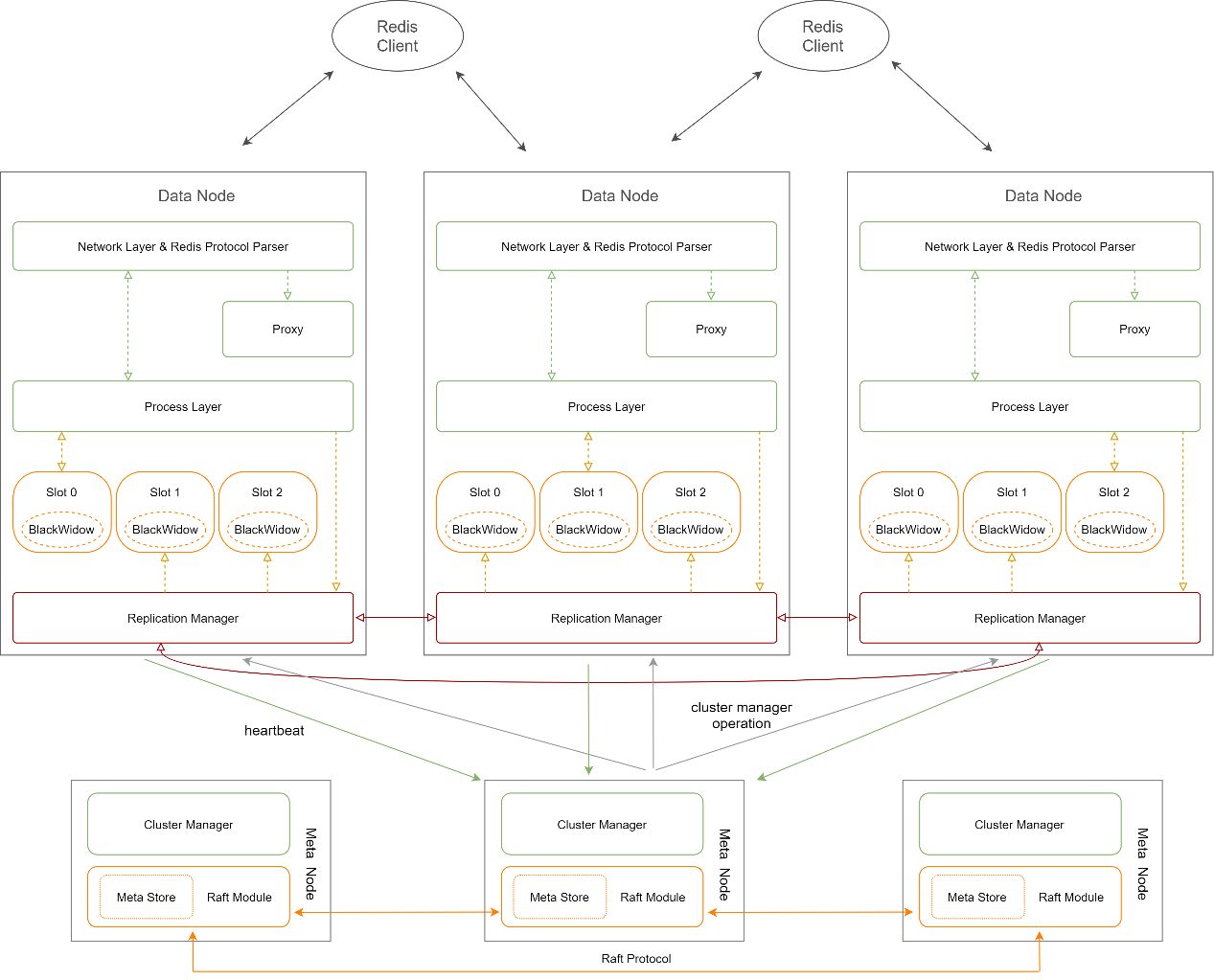
分布式模式(Sharding): Sharding 模式下,将用户存储的数据集合称为 Table,每个 Table 切分成多个分片,每个分片称为 Slot,对于某一个 KEY 的数据由哈希算法计算决定属于哪个 Slot。将所有 Slots 及其副本按照一定策略分散到所有的 Pika 实例中,每个 Pika 实例有一部分主 Slot 和一部分从 Slot。在 Sharding 模式下,Slot 被用来分主从,而不再使用 Pika 实例。Slot 在 Pika 上的物理存在形式是一个文件目录。
以上就是Redis存储系统Pika架构设计的方法是什么的详细内容,更多请关注其它相关文章! 内容来自samhan